Load Data From Snowflake

Overview
Snowflake is a data platform built for the cloud that allows for fast SQL queries. This example shows how to query data in Snowflake and pull into Saturn Cloud for data science work. We will rely on the Snowflake Connector for Python to connect and issue queries from Python code.
The images that come with Saturn come with the Snowflake Connector for Python installed. If you are building your own images and want to work with Snowflake, you should include snowflake-connector-python in your environment.
Before starting this, you should create a Jupyter server resource. See our quickstart if you don’t know how to do this yet.
Process
Add Your Snowflake Credentials to Saturn Cloud
Sign in to your Saturn Cloud account and select Credentials from the menu on the left.
This is where you will add your Snowflake credential information. This is a secure storage location, and it will not be available to the public or other users without your consent.
At the top right corner of this page, you will find the New button. Click here, and you will be taken to the Credentials Creation form.
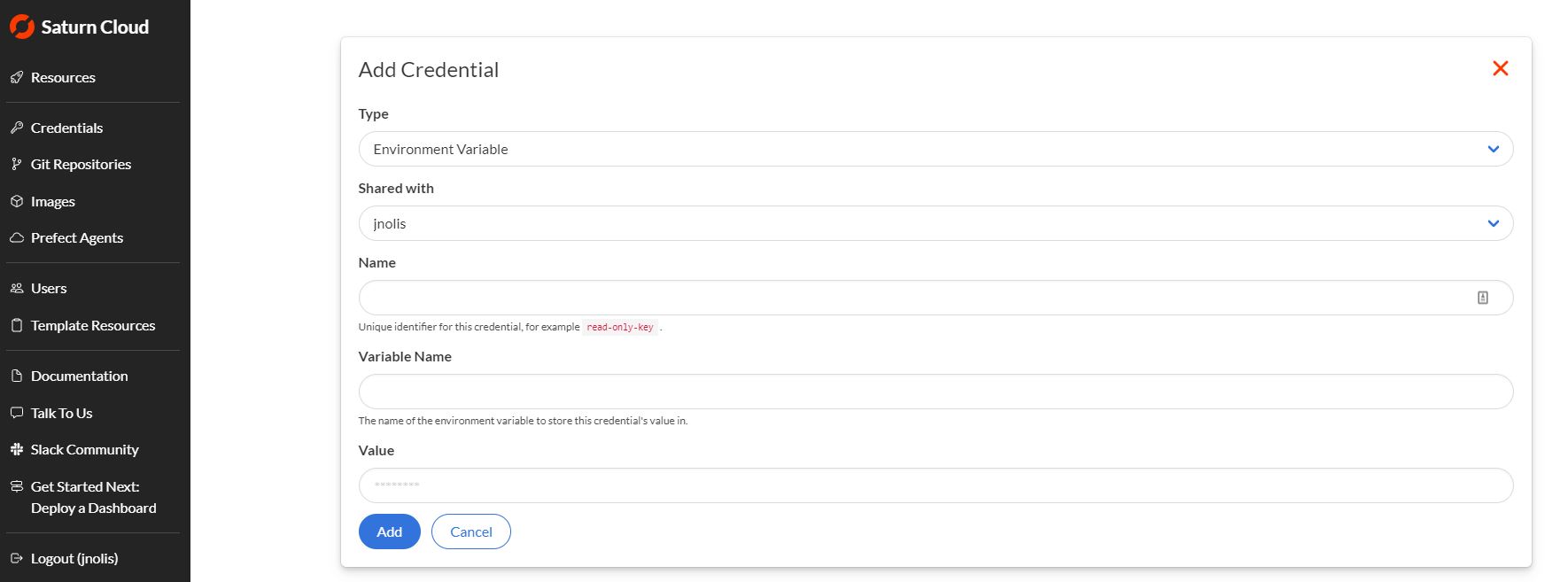
You will be adding three credentials items: your Snowflake account id, username, and password. Complete the form one time for each item.
| Credential | Type | Name | Variable Name |
|---|---|---|---|
| Snowflake account | Environment Variable | snowflake-account | SNOWFLAKE_ACCOUNT |
| Snowflake username | Environment Variable | snowflake-user | SNOWFLAKE_USER |
| Snowflake user password | Environment Variable | snowflake-password | SNOWFLAKE_PASSWORD |
Enter your values into the Value section of the credential creation form. The credential names are recommendations; feel free to change them as needed for your workflow.
If you are having trouble finding your Snowflake account id, it is the first part of the URL you use to sign into Snowflake. If you use the url https://AA99999.us-east-2.aws.snowflakecomputing.com/console/login to login, your account id is AA99999.
With this complete, your Snowflake credentials will be accessible by Saturn Cloud resources! You will need to restart any Jupyter Server or Dask Clusters for the credentials to populate to those resources.
Connect to Data
From a notebook where you want to connect to Snowflake, you can use the credentials as environment variables and provide any additional arguments, if necessary.
import os
import snowflake.connector
conn_info = {
"account": os.environ["SNOWFLAKE_ACCOUNT"],
"user": os.environ["SNOWFLAKE_USER"],
"password": os.environ["SNOWFLAKE_PASSWORD"],
"warehouse": "MY_WAREHOUSE",
"database": "MY_DATABASE",
"schema": "MY_SCHEMA",
}
conn = snowflake.connector.connect(**conn_info)
If you changed the variable name of any of your credentials, simply change them here for them to populate properly.
Note: A running warehouse is required to actually access any data.
Now you can simply query the database as you would on a local machine.
